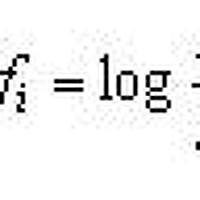-
확장 불리언 모델의 특징
- 기존 불리언 모델에 순위부여 기능을 추가하기 위하여 개발
-
확장 불리언 모델의 종류
-
- 퍼지집합 모델
- MMM(Mixed Min and Max) 모델 =Waller-Kraft 모델
- Paice 모델
- P-Norm 모델
- Infinite-One 모델
-
불리언 모델의 제약사항과 해결방안
- 정확한 비교만 가능하다 -> 근접연산이 가능하도록 수정
-
불리언 연산에 대한 엄격한 해석 -> 적당한 선에서 융통성 부여
- 불리언모델의 색인어에 대한 문헌가중치는 0 또는 1 인데 이것을 [0,1] 범위로 수정한다.
-
예: 질의가 "A AND B AND C AND D"인 경우,
- 불리언모델은 A,B,C,D중 1개라도 일치하지 않으면 검색하지 않는다.
- ->사용자는 4개의 검색어중 3개만 적합한 문서도 만족할 수 있다.
-
예: 질의가 "A OR B OR C OR D"인 경우
- 불리언 모델은 검색어중 1개 일치하는 문서와 4개 일치하는 문서가 모두 같은 중요도를 갖는다. (순위가 없다.)
- ->사용자는 검색어가 일치하는 개수에 따라 중요도(적합성, 유사도)이 다르다고 생각한다.
- 불리언모델은 검색결과에 순위가 없다. -> 검색결과에 순위 부여
- 불리언모델은 색인어에 대한 가중치가 없다. -> 색인시 색인어에 가중치 부여
- 불리언모델은 질의용어에 대한 가중치가 없다. -> 질의의 검색어에 가중치 부여
-
퍼지집합 모델
- 불리언 연산 AND, OR 을 각 검색어의 가중치에 대한 MIN, MAX 값으로 계산한다.
-
문헌-질의 유사도

-
MMM(Mixed Min and Max) 모델 =Waller-Kraft 모델
- 퍼지집합 모델의 변형
- 색인어에 대한 가중치중 최대, 최소값만 이용
-
문헌-질의 유사도
-
MMM 예제
-
조건
- 질의= A OR B OR C
- 가중치(A,B,C) = 0.5, 0.8, 0.6
- r=0.7
-
결과
- max=0.8, min=0.5
- SIM(D,Q) = (1-0.7)*0.5 + 0.7*0.8 = 0.71
-

-
Paice 모델
-
- 퍼지집합 모델의 변형
-
모든 색인어의 가중치 이용
- 색인어를 가중치순으로 정렬하는데 비용 필요
-
문헌-질의 유사도
-
Paice 예제
-
-
조건
- 질의= A OR B OR C
- 가중치(A,B,C) = 0.5, 0.8, 0.6
- r=0.7
-
결과
- 불리언연산자가 OR이므로, 내림차순으로 정렬: 0.8, 0.7, 0.5
- SIM(D,Q) = (0.70*0.8 + 0.71*0.6 + 0.72*0.5) / (0.70+ 0.71+0.72)
= 1.645/2.19 = 0.6689
-

-
P-Norm 모델
-
거리기반 접근법
- 문헌에 포함된 용어 n개에 대하여 n차원 공간 좌표 이용.
- OR 질의는 (0,0,0,....0) 좌표로 부터의 거리 내림차순으로 정렬하여 문헌가중치 부여 (????)
- AND 질의는 (0,0,0,....0) 좌표로 부터의 거리 오름차순으로 정렬하여 문헌가중치 부여 (????)
-
문헌-질의 유사도
-
상관계수 p
- 불리언모델에서는 엄격한 계산을 하므로 ∞, 간단하계 계산할 때 1 사용
- P값이 1보다 클 때 많은 계산 비용이 필요(지수계산)
-
질의용어에 대한 가중치 a
- w, (1-w) 에 a를 곱하여 사용할 수 있다
-
Paice 예제
-
조건
- 질의= A OR B OR C
- 가중치(A,B,C) = 0.5, 0.8, 0.6
- w =0.5, p=2
-
결과
- 분모= 0.52 + 0.52 +0.52 = 0.75
- 분자= (0.5*0.5)2 + (0.5*0.8)2 + (0.5*0.6)2 = 0.3125
- SIM(D,Q) = (0.3125/0.75)1/2 = 0.6455
-
-


- 확장불리언 모델용 자료구조 설계
-
-
문헌 자료구조
- 문헌가중치 배열 이용: 각 색인어에 대한 가중치
- #define NUM_ITERM xxxx // 장서(문헌집합)에 포함된 색인어 수
- typedef struct
- {
- float doc_wts[NUM_ITERM]; // 문헌가중치 = 각 색인어에 대한 가중치
- } DOC_STRUCT;
-
질의 자료구조
-
- 질의안에 포함된 검색어와 불리언연산자를 노드로 하는 트리구조 이용
-
질의 자료구조 구성
- 질의 식별자
-
질의노드 배열(질의 트리): 색인용어 또는 연산자의 관계 표현
- 색인용어 또는 연산자의 배열 인덱스
- 왼쪽 자식노드
- 오른쪽 자식노드
- 색인용어 배열: 색인어 가중치
- 연산자 배열: 불리언 연산자 종류 및 가중치
-
- typedef struct
- {
- long query_id; // 질의 식별자
- TREE_NODE *beg_node_array; // 질의트리 시작위치(루트)
- ITERM_TUPLE *beg_item_array; // 색인어배열 시작위치
- OP_TUPLE *beg_op_array; // 연산자배열 시작위치
- } QUERY_STRUCT; // 질의 자료구조
- typedef struct
- {
- int iterm_op_index; // 색인어 또는 불리언연산자에 대한 배열번호
- short child_index; // 첬째 자식노드의 노드번호 (A OR B OR C에서 A)
- short sibling_index; // 오른쪽 형제노드의 배열번호 (A OR B OR C에서 A의 형제노드는 B, B형제노드는 C, C는 형제노드가 없다)
- } TREE_NODE; // 질의 트리 자료구조
- typedef struct
- {
- long iterm_num; // 질의안의 색인어 식별자
- float iterm_wt; // 질의안의 색인어 가중치(P-norm에서만 사용)
- } ITERM_TUPLE; // 질의안의 색인어 자료구조
- typedef struct
- {
- int op_type; // 불리언연산자 종류 ( AND, OR, NOT ...)
- long op_coeff; // 불리언연산자별 상관계수 (모델에 따라 다름)
- float op_wt; // 연산자에 대한 가중치(옵션)
- } OP_TUPLE; // 불리언연산자 자료구조
-

'검색 엔진' 카테고리의 다른 글
| [박혜웅] 확률 모델(probabilistic model) (0) | 2010.03.27 |
|---|---|
| [박혜웅] 랭킹 모델(ranking model) (0) | 2010.03.27 |
| [박혜웅] 적합성 피드백(relevance feedback) (0) | 2010.03.27 |
| [박혜웅] 불리언 모델 (boolean model) (0) | 2010.03.27 |
| [박혜웅] 색인 및 검색 과정 (0) | 2010.03.27 |